The Hidden Internet: What Content People Cannot Find Online
Exploring the vast digital landscape beyond search engines
When most people think of the internet, they imagine the websites they can easily find through Google, Bing, or other search engines. However, this accessible portion represents only a tiny fraction of the total digital content available online. Between 96%-99% of content on the internet is not indexed by search engines, creating a massive hidden digital universe that remains invisible to casual users.
This hidden content isn’t necessarily secret or sinister—much of it consists of legitimate, valuable information that simply isn’t designed for public discovery. Understanding what lies beyond the reach of search engines can help us appreciate the true scope and complexity of our digital world.
The Iceberg Analogy: Surface Web vs. Deep Web vs. Dark Web 
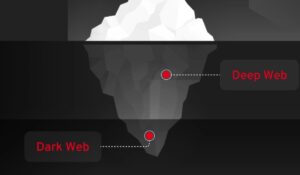
Imagine the internet as an iceberg floating in the ocean. The small portion visible above water represents the Surface Web—all the websites you can easily find through search engines. This includes public websites, blogs, news sites, and social media platforms that are openly accessible and indexed.
Below the waterline lies the Deep Web, which makes up the vast majority of online content. This isn’t hidden due to malicious intent, but rather because it’s either:
- Protected by passwords and authentication systems
- Stored in databases that search engines can’t easily crawl
- Intentionally excluded from search results by website owners
At the very bottom of our metaphorical iceberg sits the Dark Web—part of the internet that isn’t visible to search engines and requires the use of an anonymizing browser called Tor to be accessed. While this represents the smallest portion, it often receives the most attention due to its association with anonymity and privacy.
1. Password-Protected and Private Content: The Digital Vault
The largest category of hidden content consists of information protected behind authentication systems. This digital vault contains:
Corporate and Business Data
- Internal company databases: Employee records, financial reports, strategic planning documents, and proprietary research
- Customer relationship management (CRM) systems: Client information, sales data, and communication histories
- Enterprise resource planning (ERP) systems: Supply chain data, inventory management, and operational metrics
- Internal communication platforms: Company emails, Slack channels, Microsoft Teams conversations, and project management tools
Academic and Research Content
Content includes academic and corporate databases, newspaper or journal content, and academic library subscriptions. This encompasses:
- Scholarly databases: JSTOR, PubMed, IEEE Xplore, and thousands of specialized academic databases
- University library systems: Digital collections, rare manuscripts, and research archives
- Peer-review platforms: Editorial systems where academic papers are reviewed before publication
- Institutional repositories: Thesis databases, faculty research, and unpublished studies
Personal Digital Lives
- Social media privacy: Private profiles, direct messages, and restricted posts on platforms like Facebook, Instagram, and LinkedIn
- Email accounts: Billions of personal and professional emails stored in Gmail, Outlook, and other services
- Cloud storage: Personal files in Google Drive, Dropbox, OneDrive, and iCloud
- Banking and financial services: Account information, transaction histories, and financial planning tools
Healthcare and Legal Records
- Electronic health records (EHR): Patient information, medical histories, and treatment records
- Legal databases: Court filings, case management systems, and attorney-client communications
- Government employee systems: Personnel records, security clearance information, and internal communications
2. Database-Driven Content: The Information Warehouses
Content on the Deep Web is not found by most search engines because it is stored in a database which is not coded in HTML. These dynamic information systems include:
Library and Catalog Systems
- WorldCat: The world’s largest library catalog, containing information about books, movies, music, and other materials
- Digital archives: Historical documents, photographs, and multimedia content stored in specialized systems
- Museum databases: Art collections, archaeological findings, and cultural artifacts
- Patent databases: Detailed technical documentation of inventions and innovations
Government and Public Records
- Census data: Detailed demographic information often requiring specific queries to access
- Property records: Real estate transactions, tax assessments, and zoning information
- Court records: Legal proceedings, judgments, and case files that may not be fully digitized or searchable
- Regulatory filings: SEC documents, FDA submissions, and other regulatory data
Commercial Databases
- Product inventories: Real-time stock levels, pricing information, and product specifications
- Financial market data: Stock prices, trading volumes, and market analysis tools
- Travel booking systems: Flight schedules, hotel availability, and pricing algorithms
- Job boards: Resume databases, applicant tracking systems, and internal job postings
3. The Dark Web: The Anonymous Internet
The Dark Web represents the most mysterious portion of hidden internet content. While it requires special software like Tor (The Onion Router) to access, not all Dark Web content is illicit:
Legitimate Uses
- Privacy protection: Journalists communicating with sources in oppressive regimes
- Whistleblowing platforms: Secure channels for reporting corporate or government wrongdoing
- Censorship circumvention: Access to information in countries with strict internet controls
- Academic research: Studies on internet privacy, cybersecurity, and digital rights
Concerning Content
While we won’t detail illegal activities, the Dark Web does host marketplaces and forums that operate outside legal boundaries, highlighting the importance of cybersecurity and digital literacy.
4. Subscription and Paywall Content: Premium Information
This includes VPN (virtual private networks) and any website where pages require a username and password. The monetization of information has created significant barriers to access:
News and Media
- Premium journalism: In-depth reporting, investigative journalism, and expert analysis behind paywalls
- Specialized publications: Industry magazines, trade journals, and professional newsletters
- Archive access: Historical newspaper articles and magazine issues
- International content: Foreign news sources and regional publications
Educational and Professional Resources
- Online learning platforms: Course materials on Coursera, edX, LinkedIn Learning, and specialized training sites
- Professional development: Certification programs, skill assessments, and career guidance tools
- Technical documentation: Software manuals, API documentation, and implementation guides
- Industry reports: Market research, trend analysis, and competitive intelligence
Entertainment and Media
- Streaming services: Movies, TV shows, documentaries, and original content on Netflix, Amazon Prime, Disney+, and others
- Gaming platforms: Exclusive games, downloadable content, and online gaming communities
- Music services: High-quality audio, exclusive releases, and artist content on Spotify Premium, Apple Music, and Tidal
- Digital publications: E-books, audiobooks, and digital magazines
5. Technically Excluded Content: Intentionally Hidden
Website owners and developers often deliberately prevent certain content from appearing in search results:
SEO and Content Management
- Robots.txt exclusions: Websites can instruct search engines to avoid crawling specific pages or directories
- Noindex tags: HTML meta tags that explicitly tell search engines not to include pages in search results
- Canonical tags: Instructions that prevent duplicate content from appearing in search results
- Password-protected staging sites: Development and testing versions of websites
Dynamic and Personalized Content
- User-specific pages: Account dashboards, personalized recommendations, and customized interfaces
- Session-based content: Shopping carts, form data, and temporary user-generated content
- Geographic restrictions: Content that varies based on location or isn’t available in certain regions
- Time-sensitive material: Flash sales, limited-time offers, and event-specific information
Technical Infrastructure
- Admin panels: Content management systems, website backends, and administrative interfaces
- API endpoints: Raw data feeds and application programming interfaces not meant for public browsing
- Server configurations: Technical files, logs, and system information
- Development tools: Code repositories, testing environments, and debugging information
6. Ephemeral and Real-Time Content: Here One Moment, Gone the Next
The modern internet includes vast amounts of temporary or constantly changing content:
Communication Platforms
- Instant messaging: WhatsApp conversations, Telegram channels, and Discord servers
- Video calls: Zoom meetings, Google Meet sessions, and Skype conversations
- Live streaming: Twitch streams, YouTube Live broadcasts, and Facebook Live videos
- Temporary sharing: Snapchat stories, Instagram stories, and Twitter Fleets (discontinued)
Real-Time Data
- Stock market feeds: Live trading data, market movements, and financial indicators
- Weather systems: Meteorological data, satellite imagery, and forecasting models
- Traffic information: Real-time navigation data, public transit updates, and traffic patterns
- Sports and events: Live scores, play-by-play coverage, and real-time commentary
Social and Cultural Content
- Trending topics: Viral content that quickly disappears from relevance
- Event documentation: Live-tweeting, real-time coverage, and user-generated content from events
- Community discussions: Forum posts, Reddit threads, and comment sections that may be deleted
- User-generated content: Reviews, ratings, and testimonials that may be removed or modified
The Implications: Why This Matters
Understanding the scope of hidden internet content has several important implications:
Digital Literacy
- Research limitations: Recognizing that search engines only show a small fraction of available information
- Source verification: Understanding the difference between publicly available and authenticated sources
- Privacy awareness: Appreciating how much personal information exists beyond public view
Information Access and Equity
- Economic barriers: Many valuable resources require payment or institutional access
- Geographic limitations: Content availability varies significantly by location
- Technical requirements: Different content requires different tools and knowledge to access
Security and Privacy
- Data protection: Personal information exists in numerous databases and systems
- Corporate surveillance: Understanding how much data companies collect and store
- Government monitoring: Awareness of how authorities can access various types of digital information
Professional and Academic Impact
- Research thoroughness: Comprehensive research requires accessing multiple types of hidden content
- Competitive intelligence: Business decisions benefit from understanding the full information landscape
- Academic integrity: Proper research methodology includes awareness of diverse information sources
Conclusion: Navigating the Hidden Internet
The internet as we commonly experience it represents only the tip of a massive informational iceberg. Between 96%-99% of content on the internet is not indexed by search engines, creating a vast digital universe that remains largely invisible to casual users.
This hidden content isn’t necessarily secretive or malicious—much of it consists of valuable, legitimate information that simply isn’t designed for public discovery. From academic databases and corporate records to personal communications and real-time data feeds, the hidden internet contains the infrastructure that makes our digital world function.
As we become increasingly dependent on digital information, understanding the limitations of search engines and the scope of hidden content becomes crucial for digital literacy. Whether you’re a student conducting research, a professional seeking comprehensive information, or simply a curious individual, recognizing what lies beyond the surface web can help you become a more informed and effective digital citizen.
The next time you search for information online, remember that you’re only seeing the smallest fraction of what’s actually available. The real internet is far larger, more complex, and more fascinating than what meets the eye—and that’s both the challenge and the opportunity of our connected age.
Have you discovered interesting resources in the deep web or behind paywalls? Share your experiences with navigating the hidden internet in the comments below.

